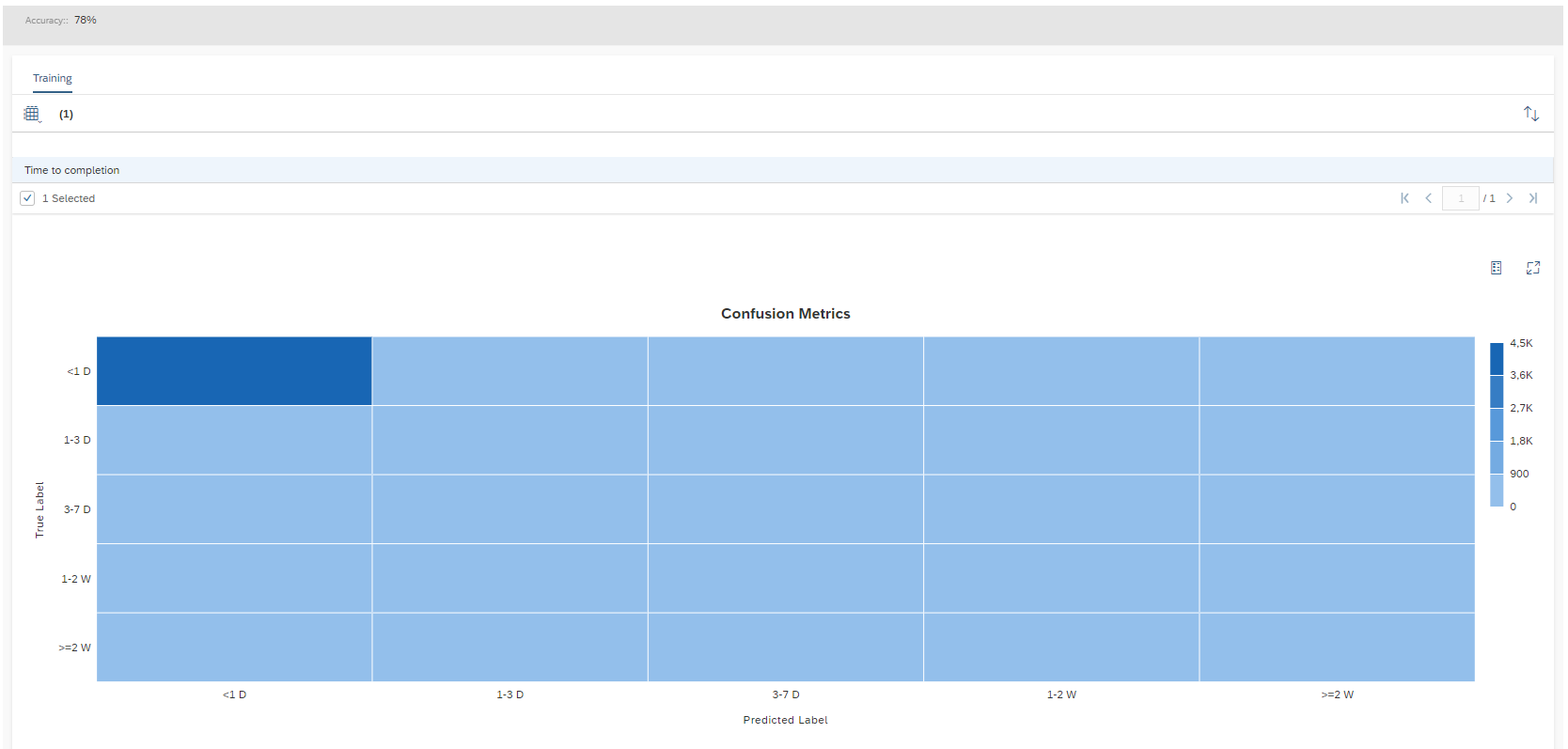
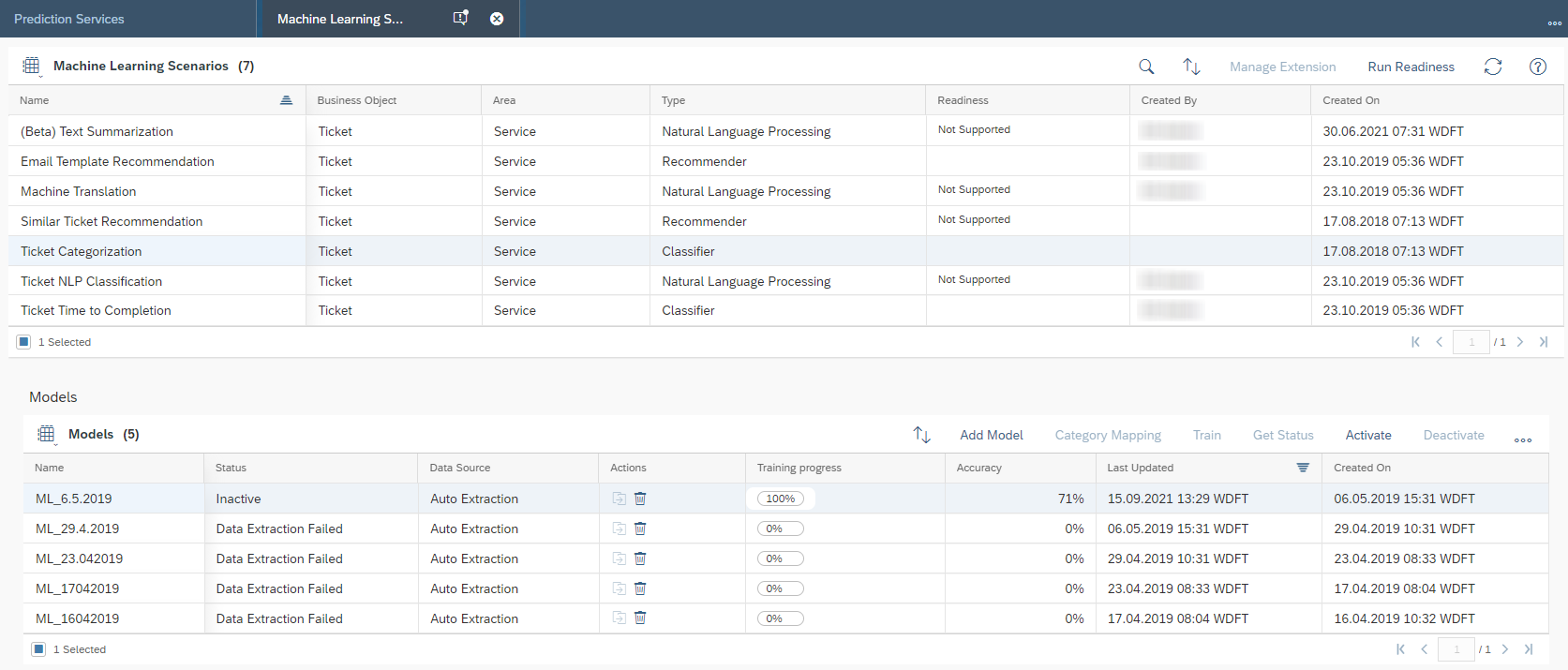

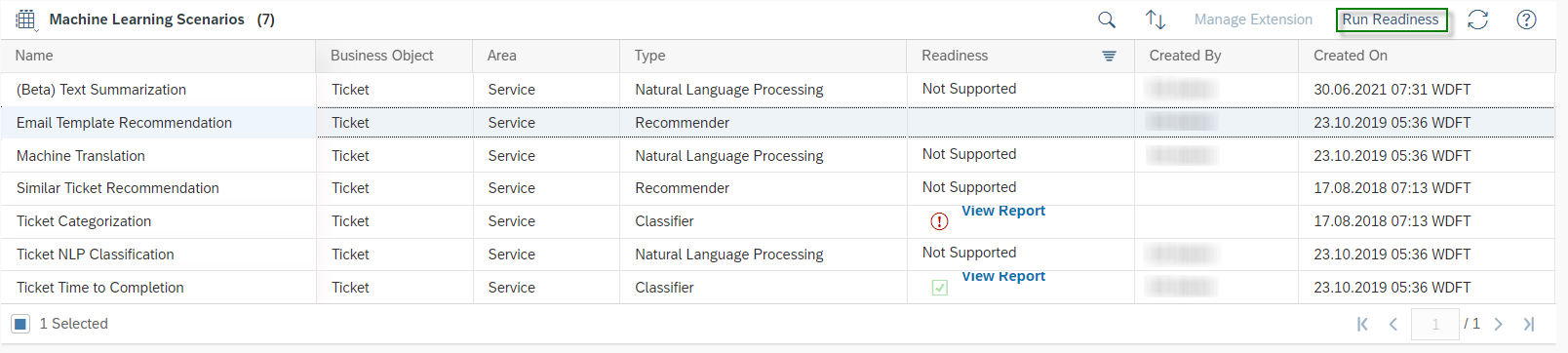

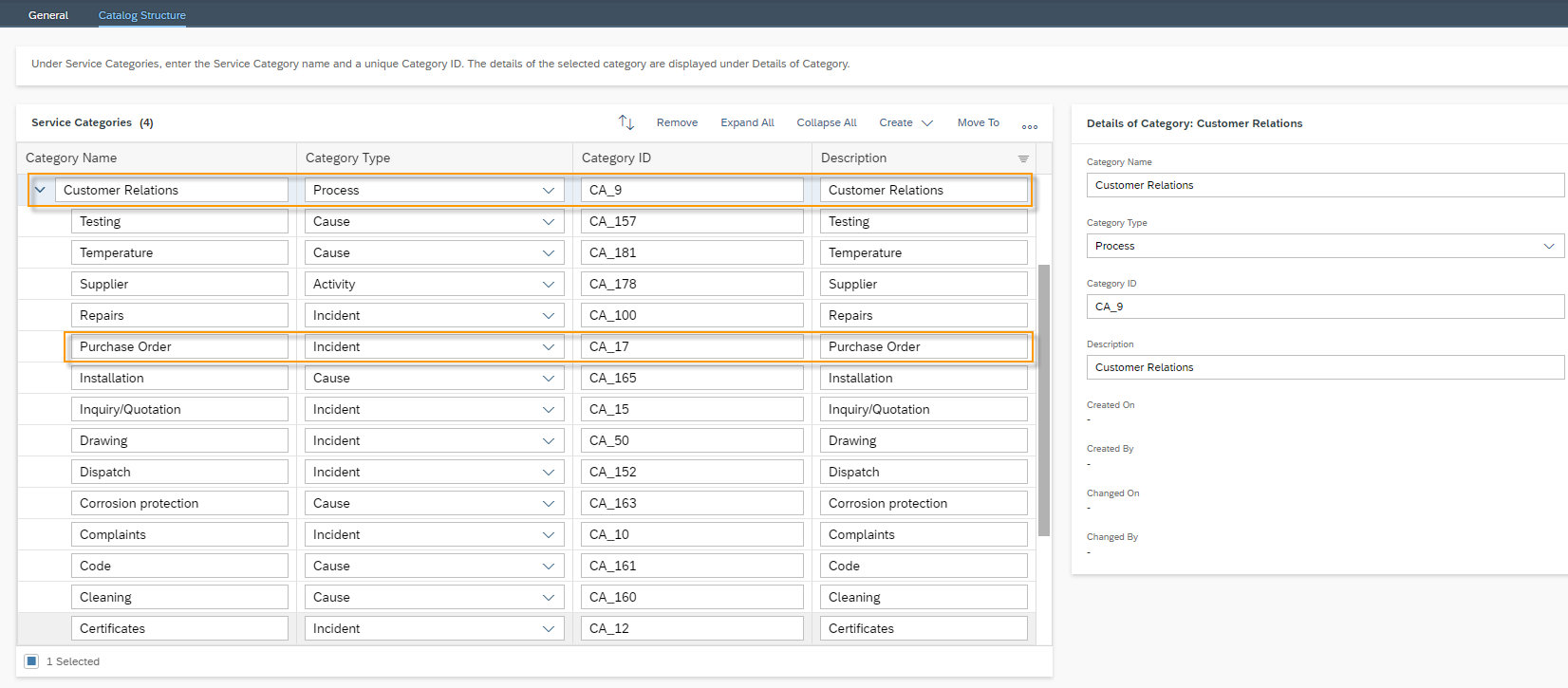
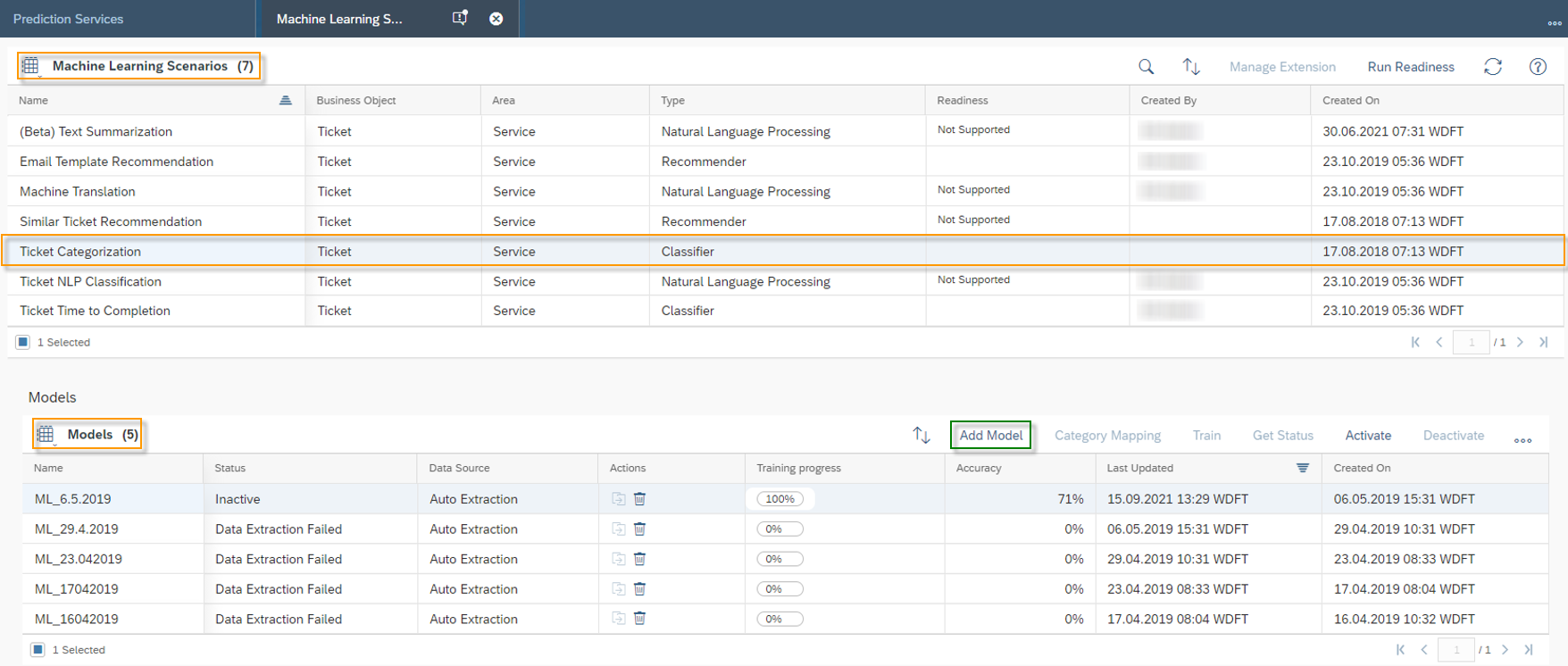

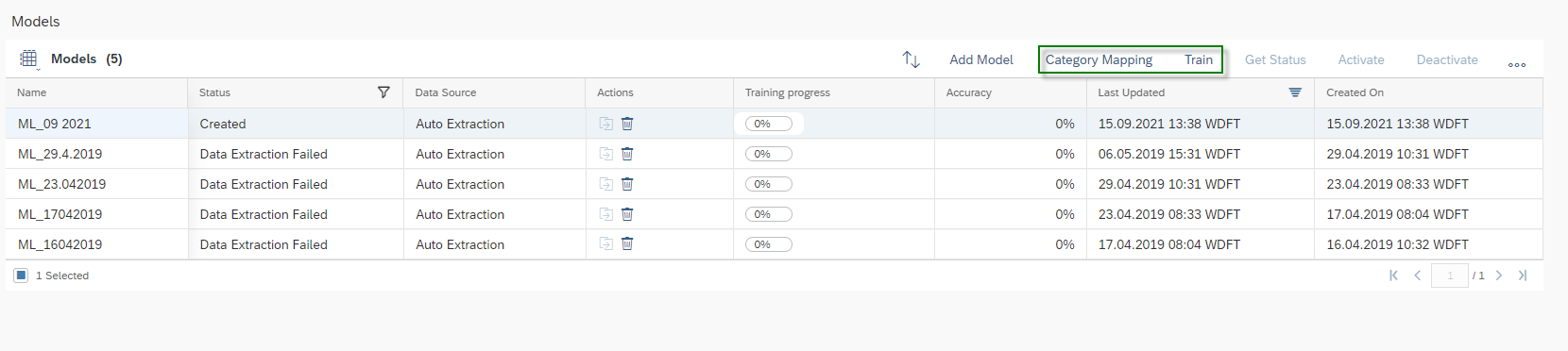
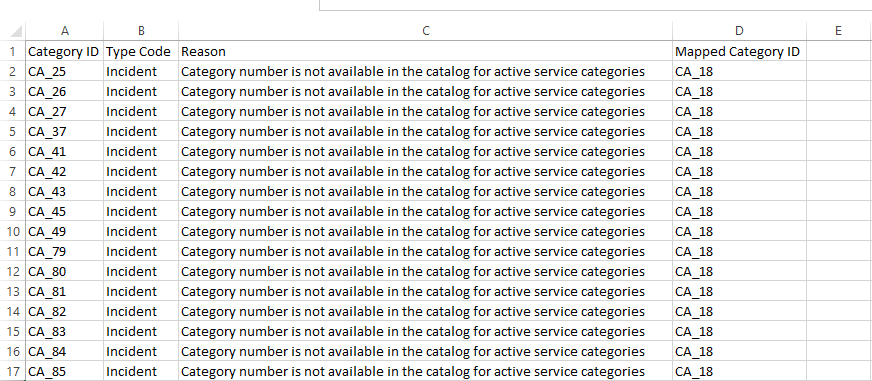



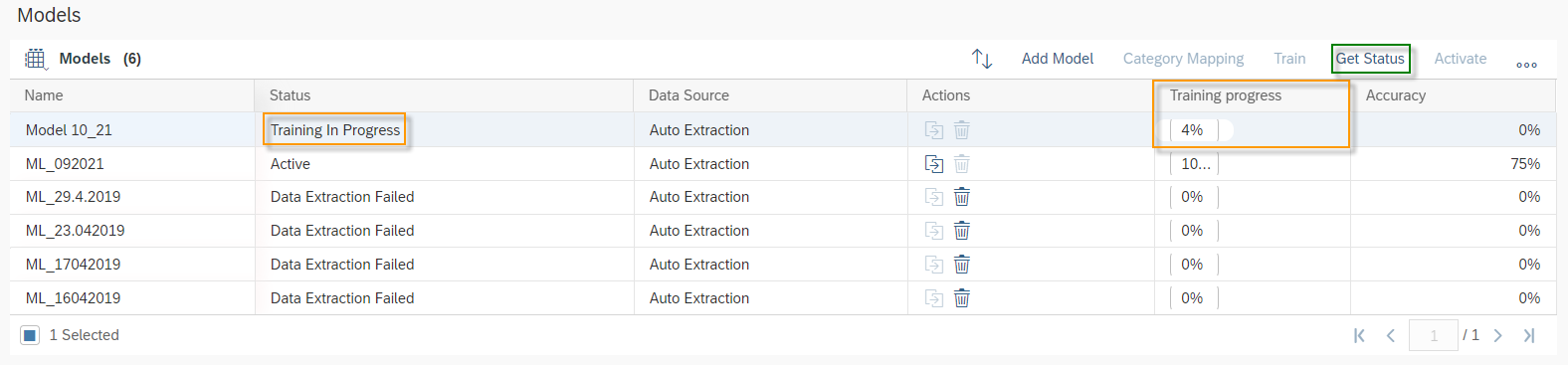
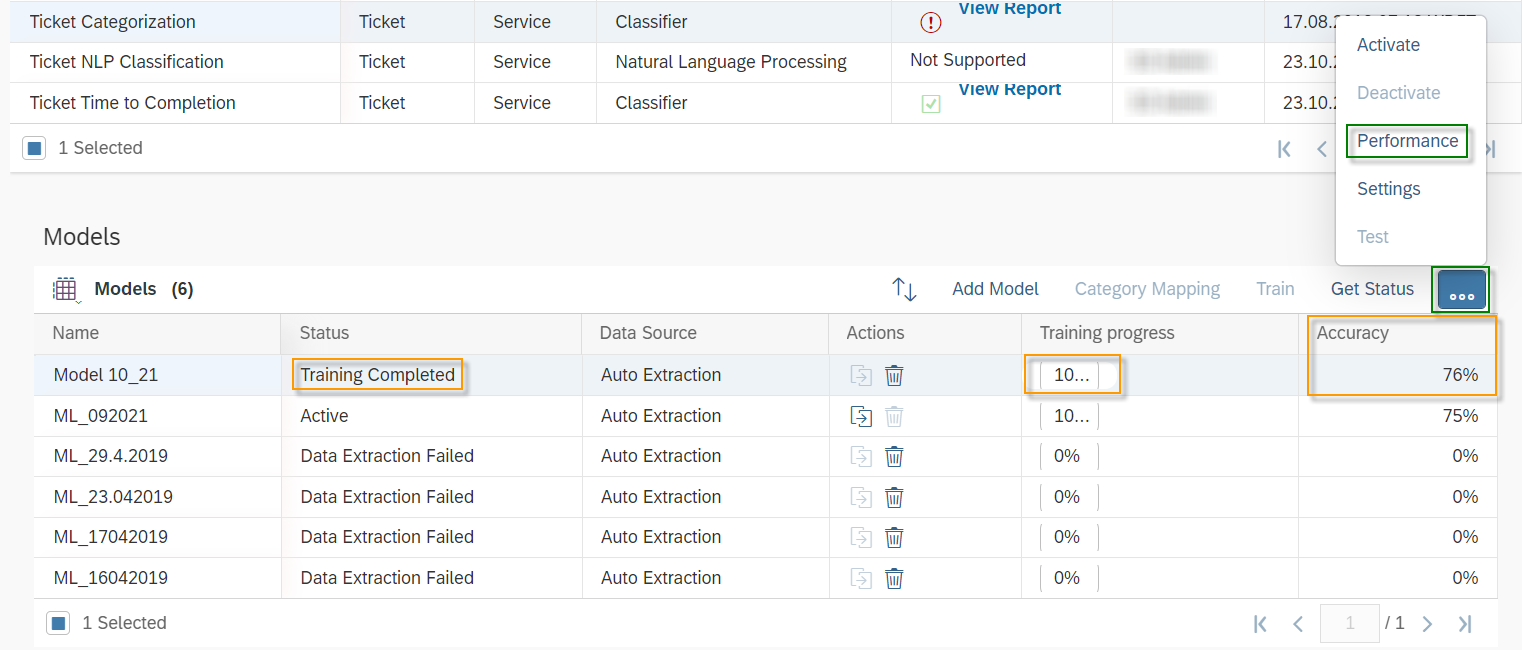
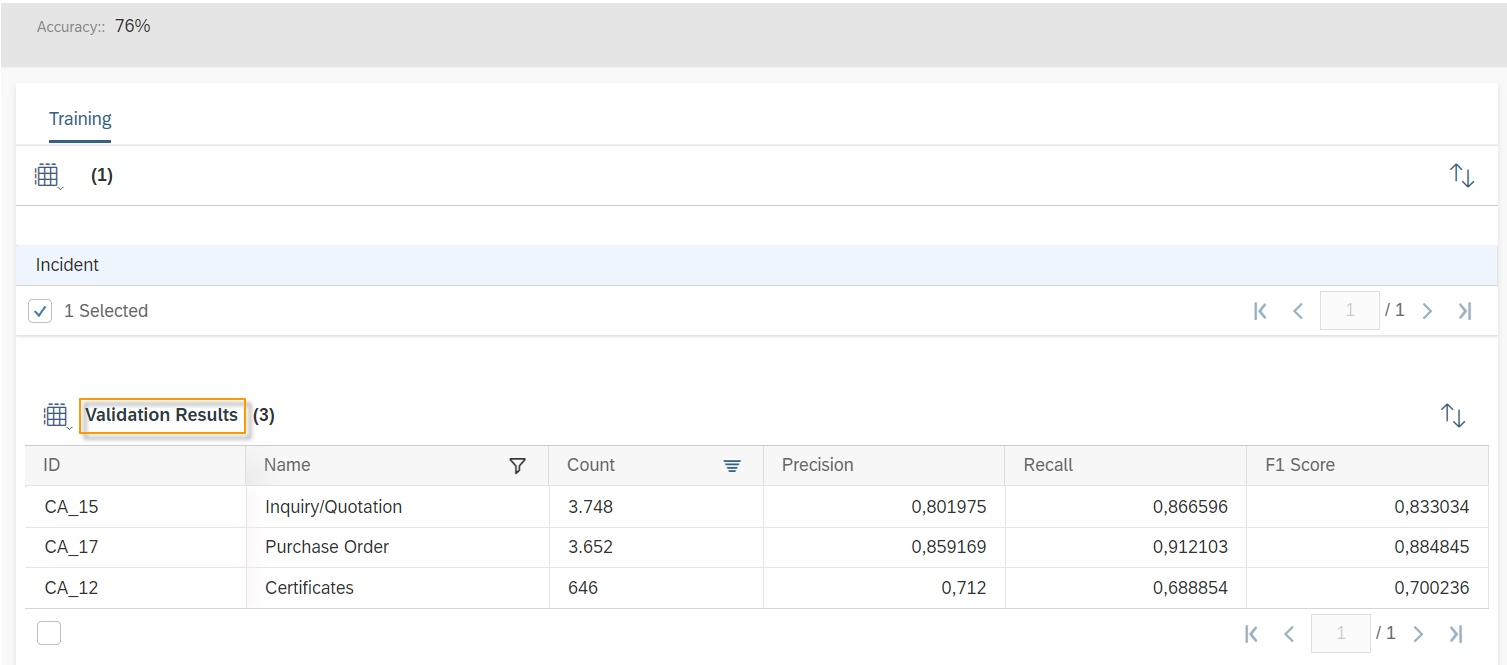
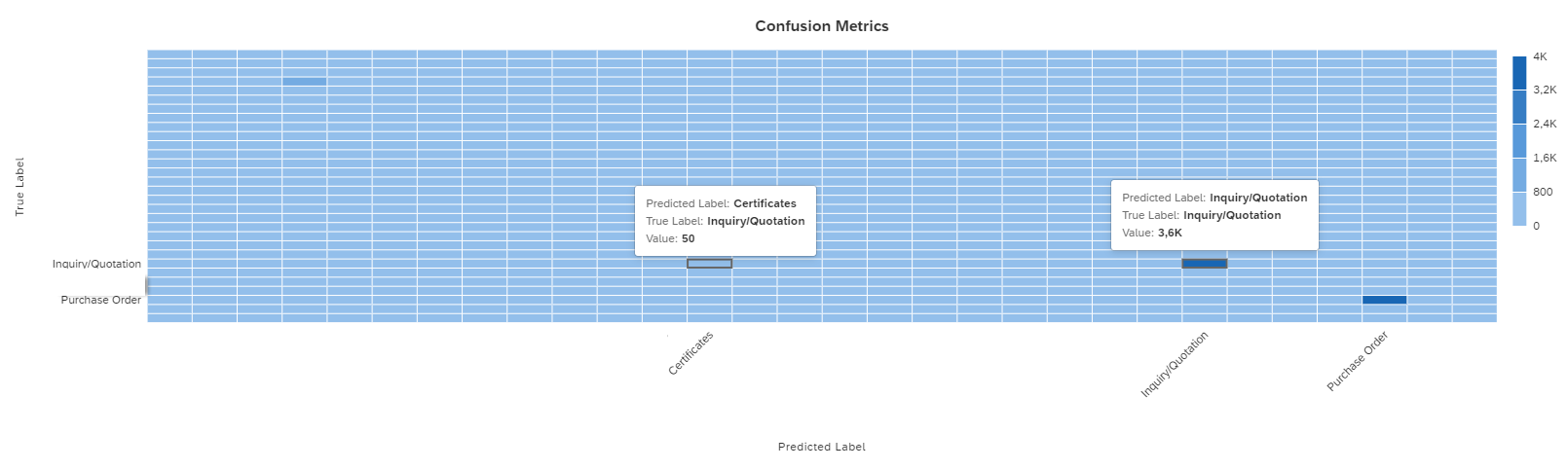
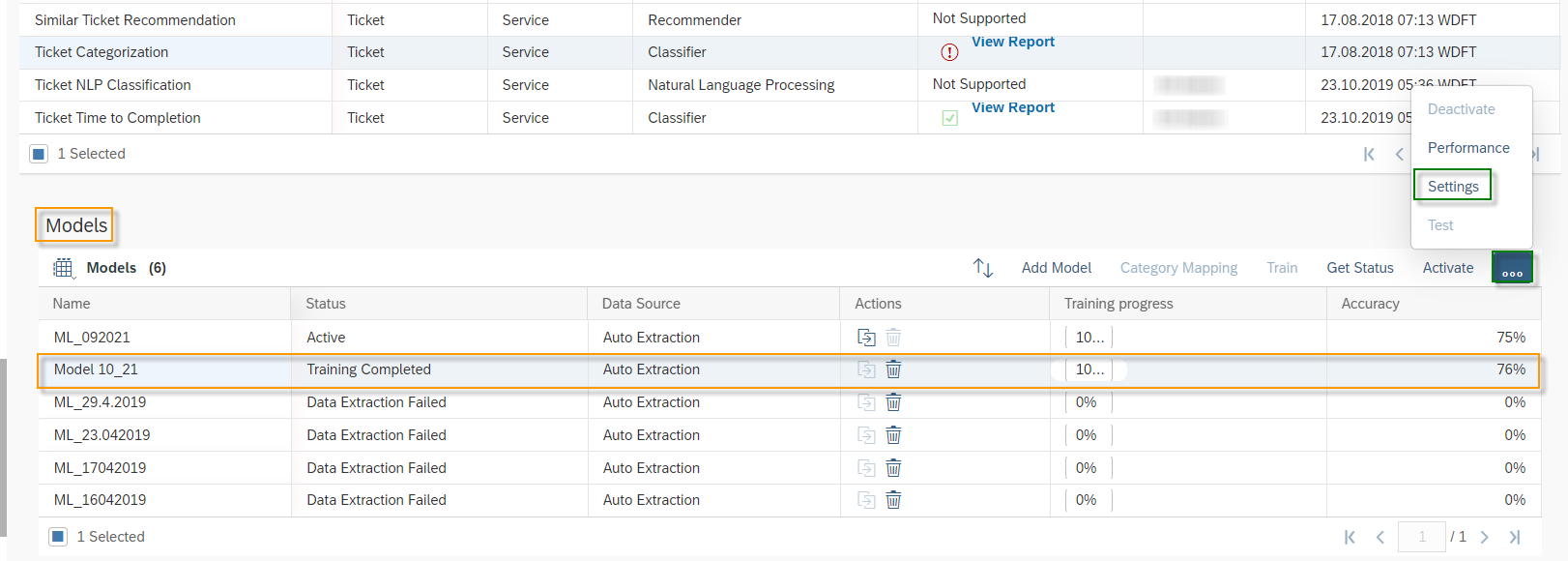
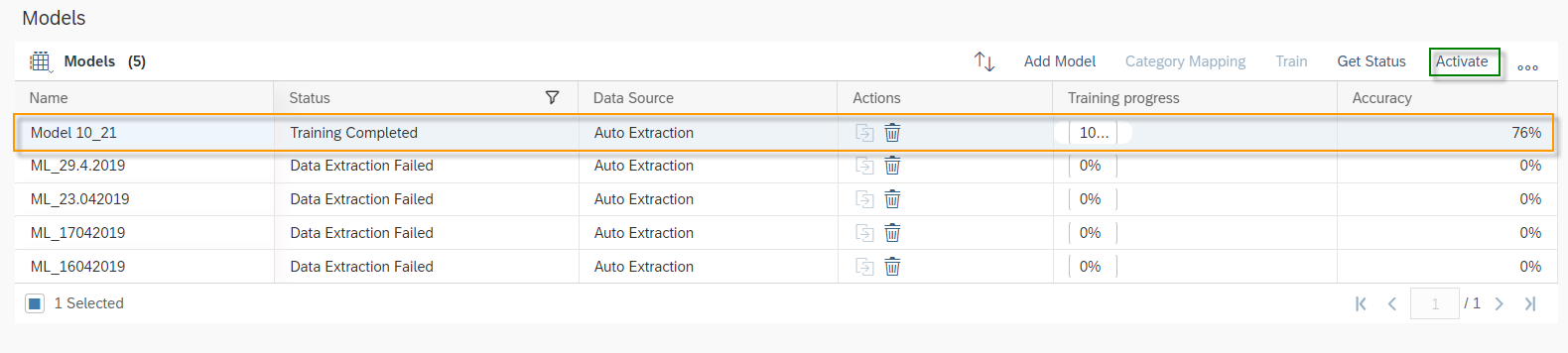
Once the training is completed the Status will be changed to Training Completed and Training progress will be on 100%. SAP Leonardo® component returns an Accuracy of the model. The Accuracy is defined as the percentage of correct predictions for the test data. This means that after training, each ticket is categorized by the machine and compared with the actual category. The 60% mark can be seen as a good thumb value for a good accuracy of a model. In general, of course, the higher the accuracy, the better. However, an accuracy of 60% or more is considered good. In the shown example the Accuracy is 76%, which means 76% of all trained data would be predicted to the correct Incident Category. Further data on the performance of the model can be viewed by clicking on More Options Button ![]() and then on Performance.
and then on Performance.

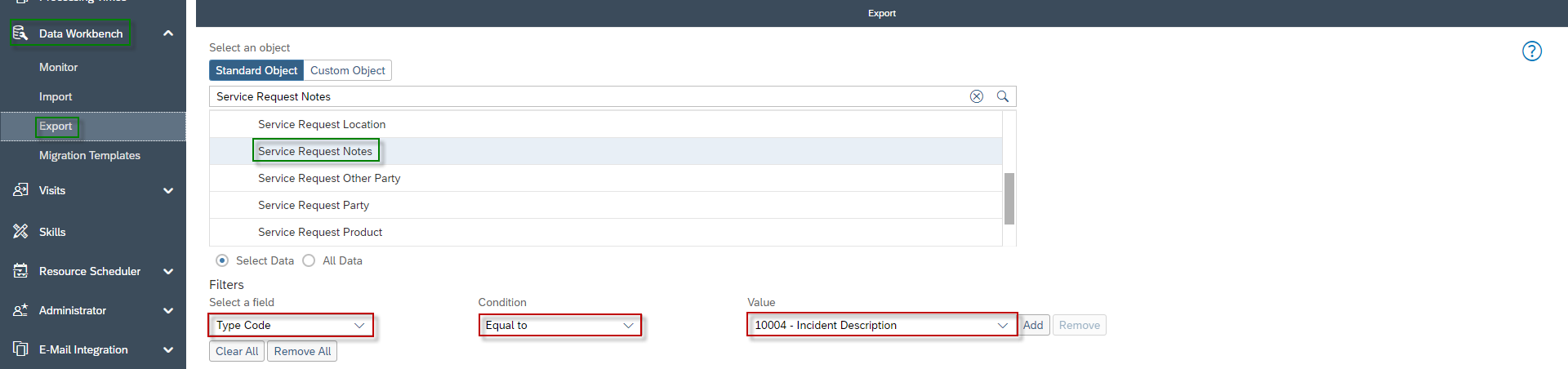
Open the data export with the Ticket Description in a text editor – e.g. Notepad ++. Then make sure that the maximum of characters of each Ticket Description is below 255. Otherwise, this will lead to errors, while uploading the .csv-File. Since the ticket description is the initial customer mail, it can contain breaks, commas, and semicolons. All these characters you don’t want to have in a .csv file. To remove these characters, use the Find and Replace function of your editor and proceed as follows:
- Marc all text in your file – mostly with CTL + A
- Replace ,” with …” to keep the comma between Ticket ID and Text, when you remove the commas later
- Remove all commas and replace , with nothing
- Remove all semicolons and replace ; with nothing
- Remove all breaks and replace \n with nothing
- Get the comma between Ticket ID and Text back and replace …” with ,”
- Replace “2 with “\n2 to get a break between each dataset back
- Define the Header with Ticket ID and Description
- Save the new .csv-File
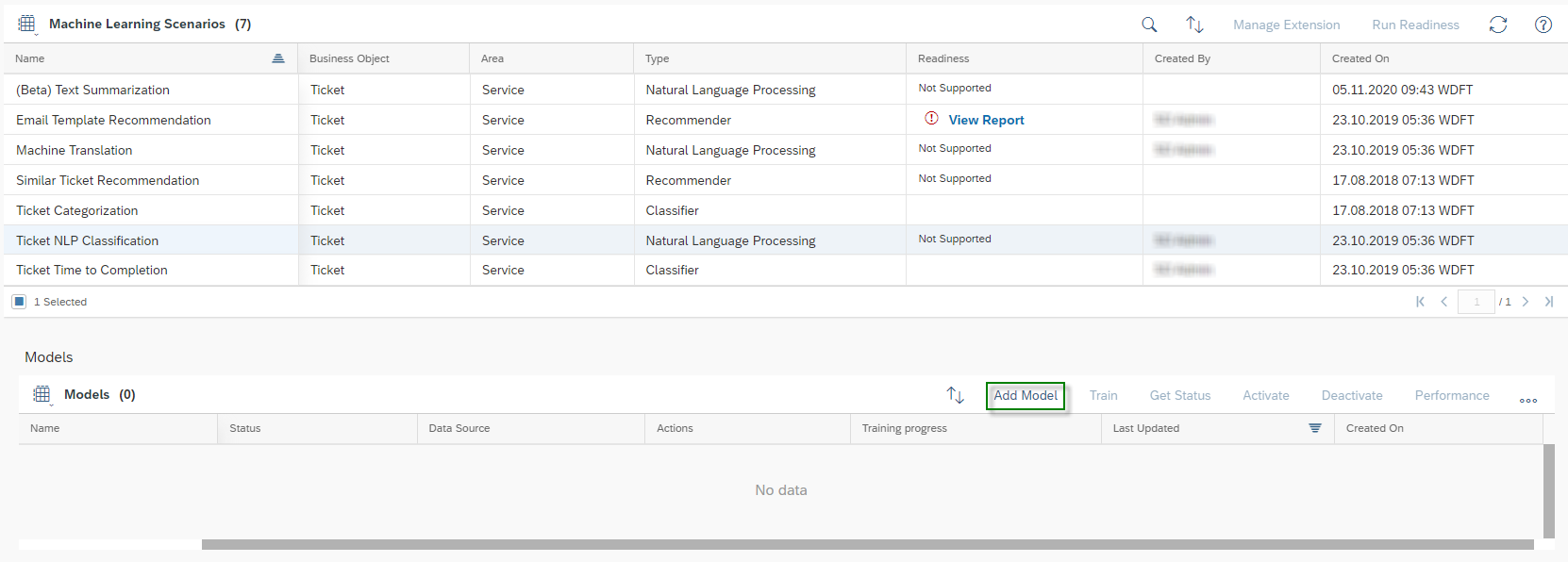
2. Upload the .csv File
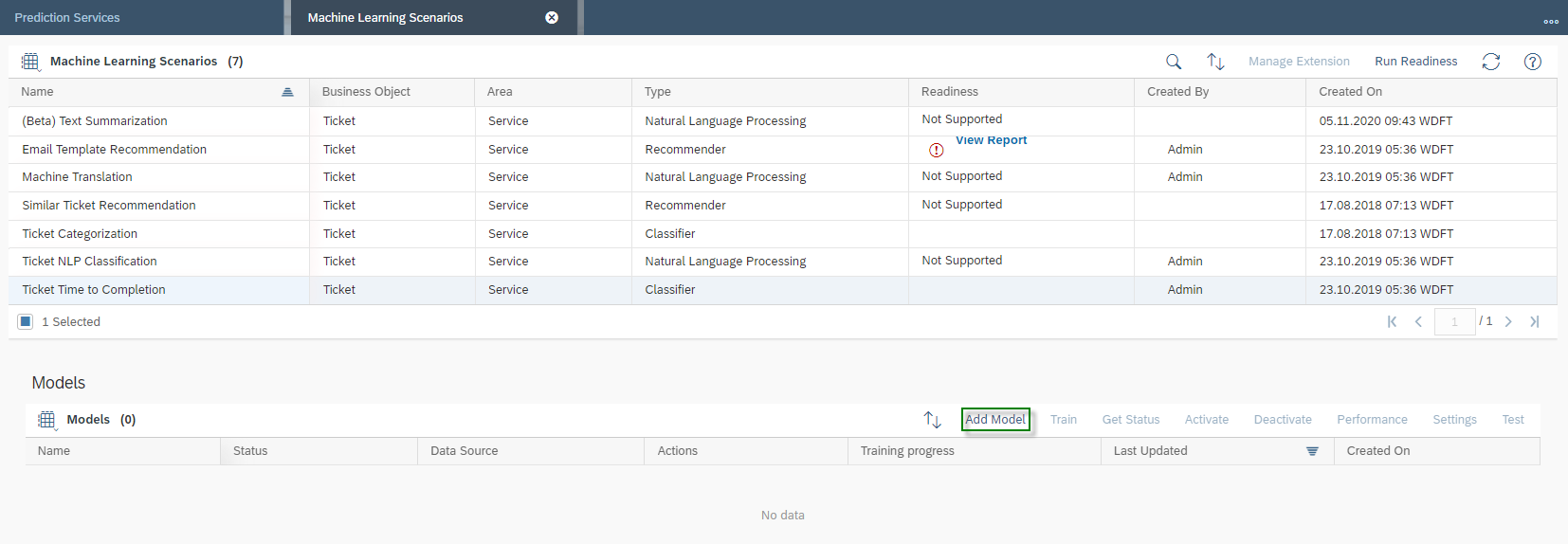
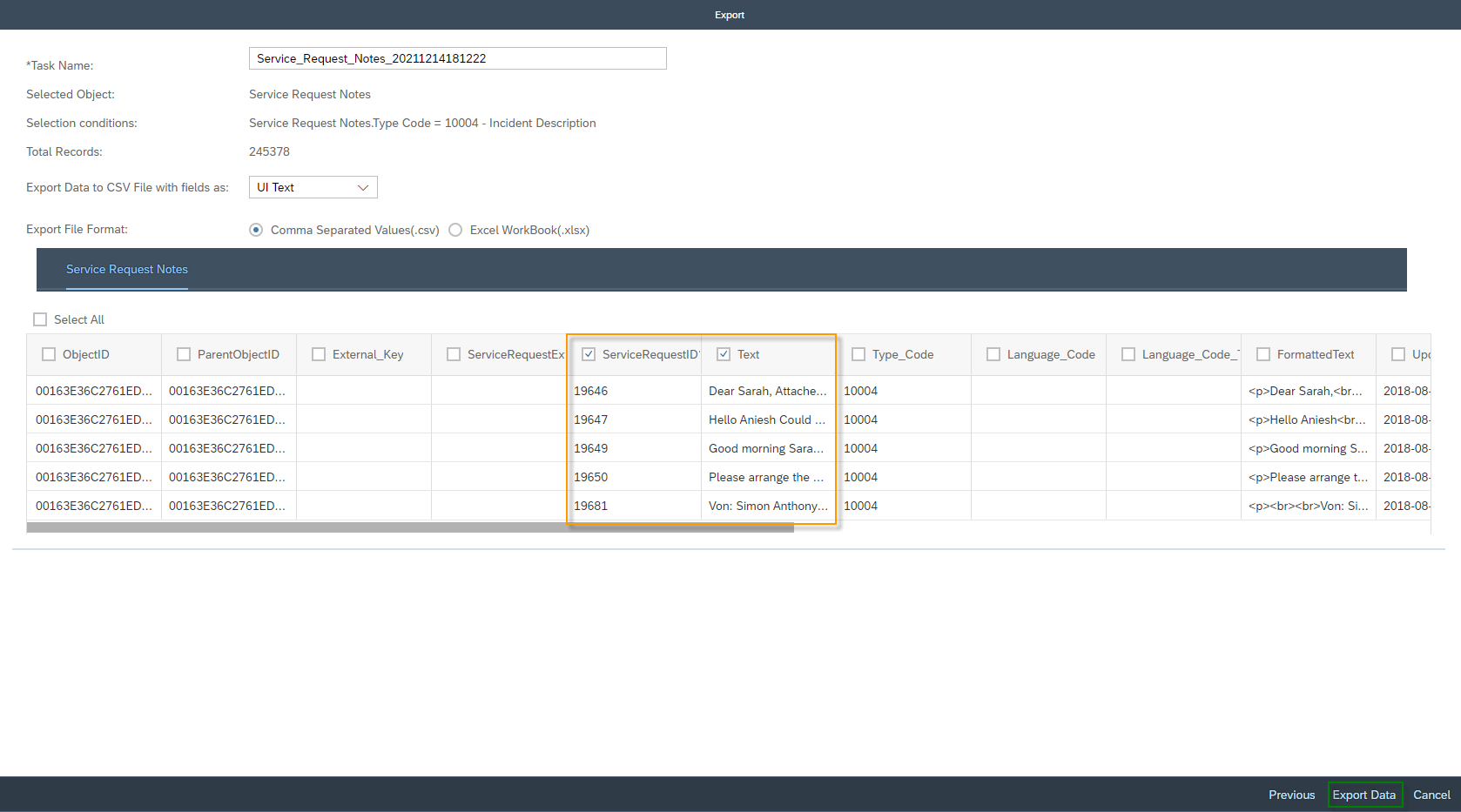
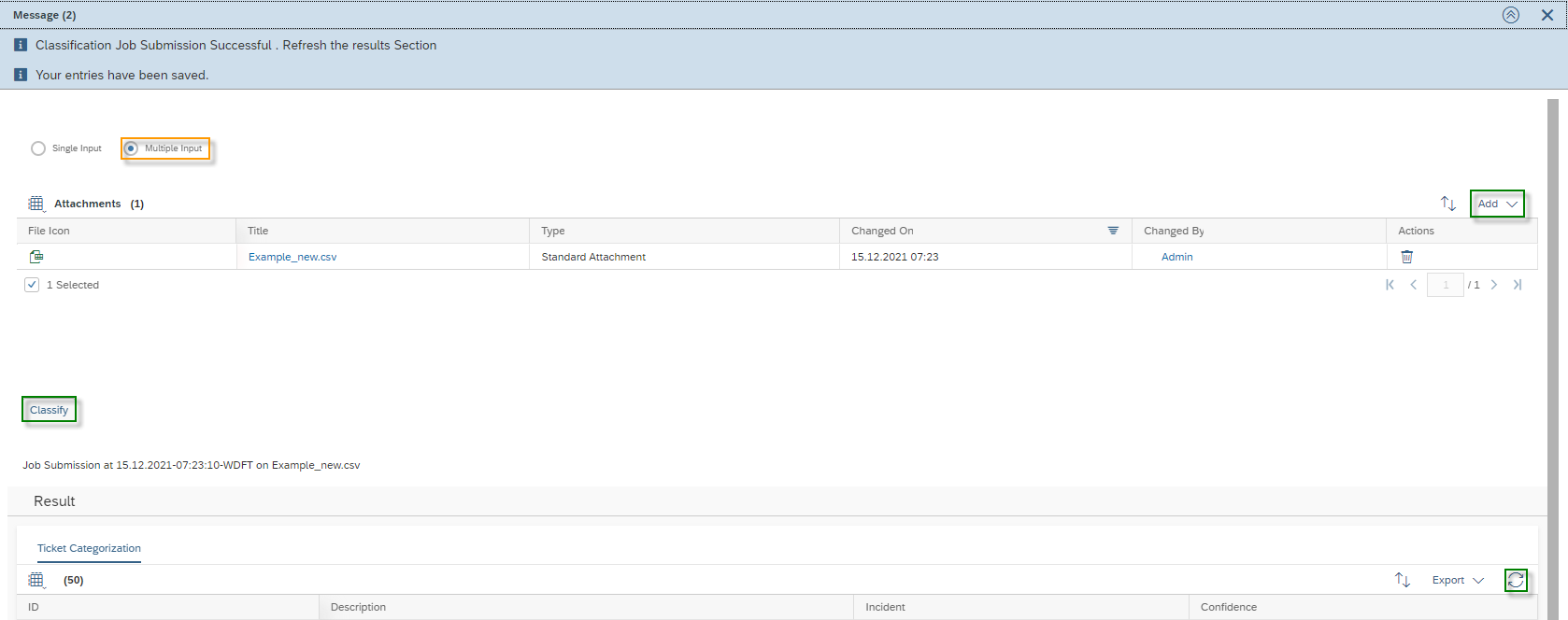
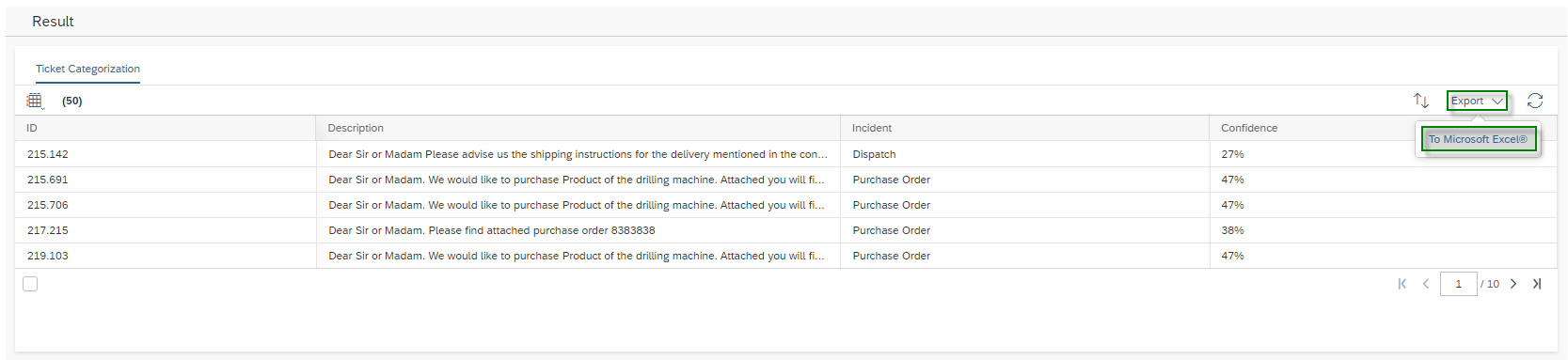
Select the machine learning scenario Ticket Categorization, then its activated model and click Test. Select the Multiple Input section. Upload your .csv file with the Add button and click on the Classify button. You will receive a message saying “Classification Job Submission Successful. Refresh the results Section”. Depending on how much data you have in your .csv file – a maximum of 100 is allowed – the analysis will take a little longer. However, click on Refresh ![]() in the Result Section.
in the Result Section.






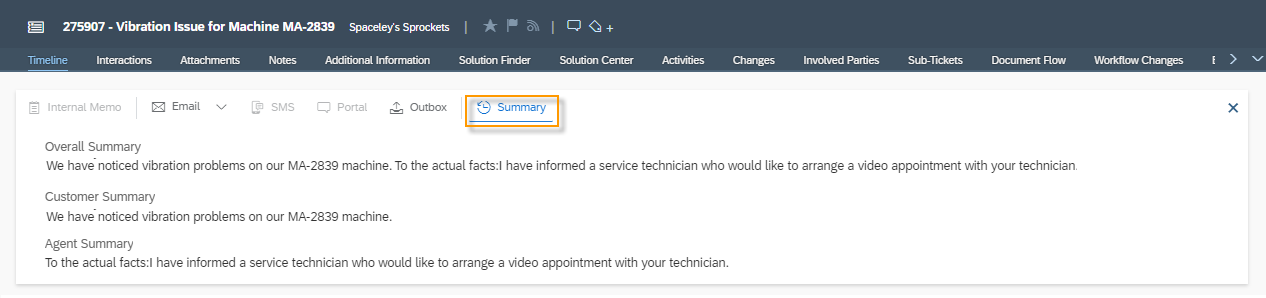

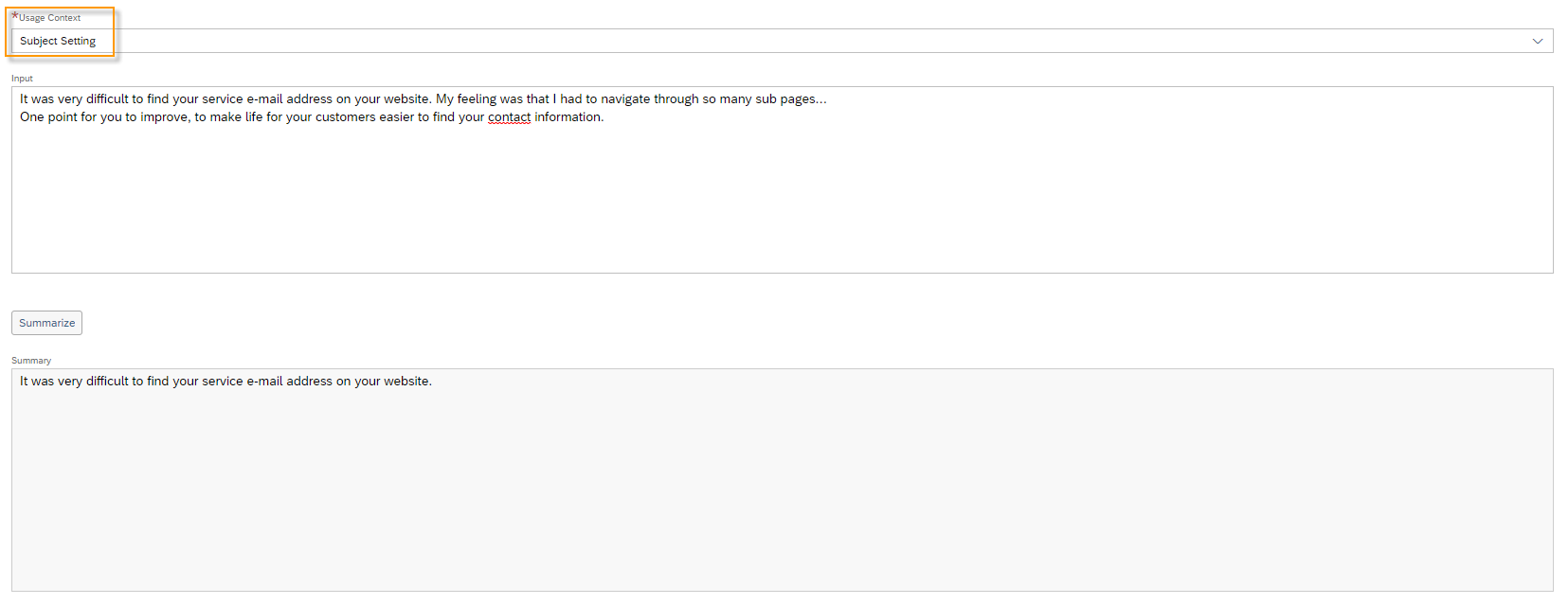
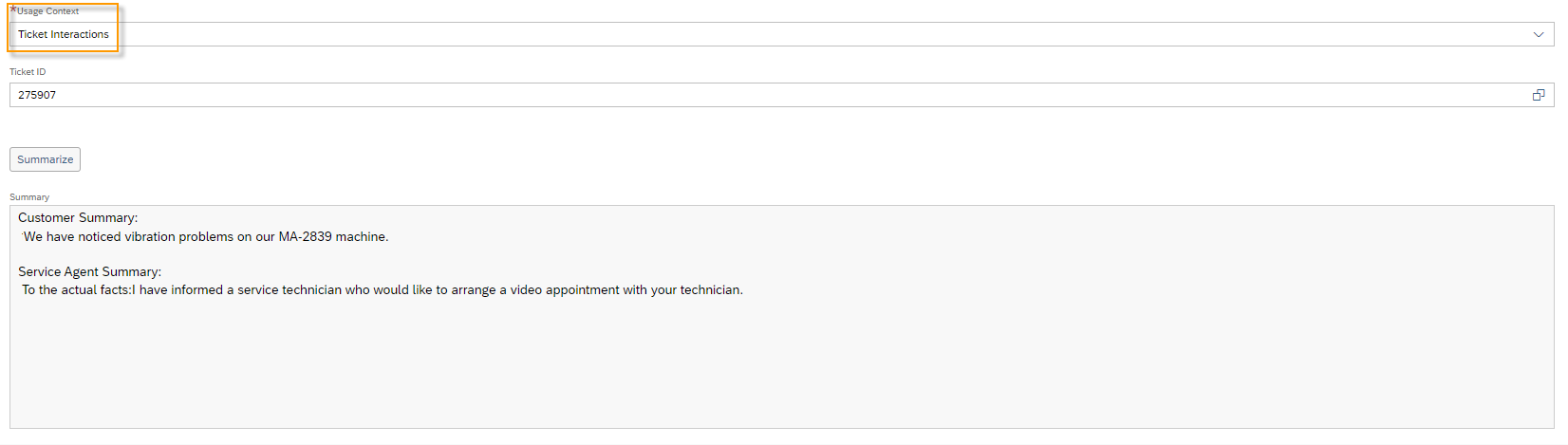




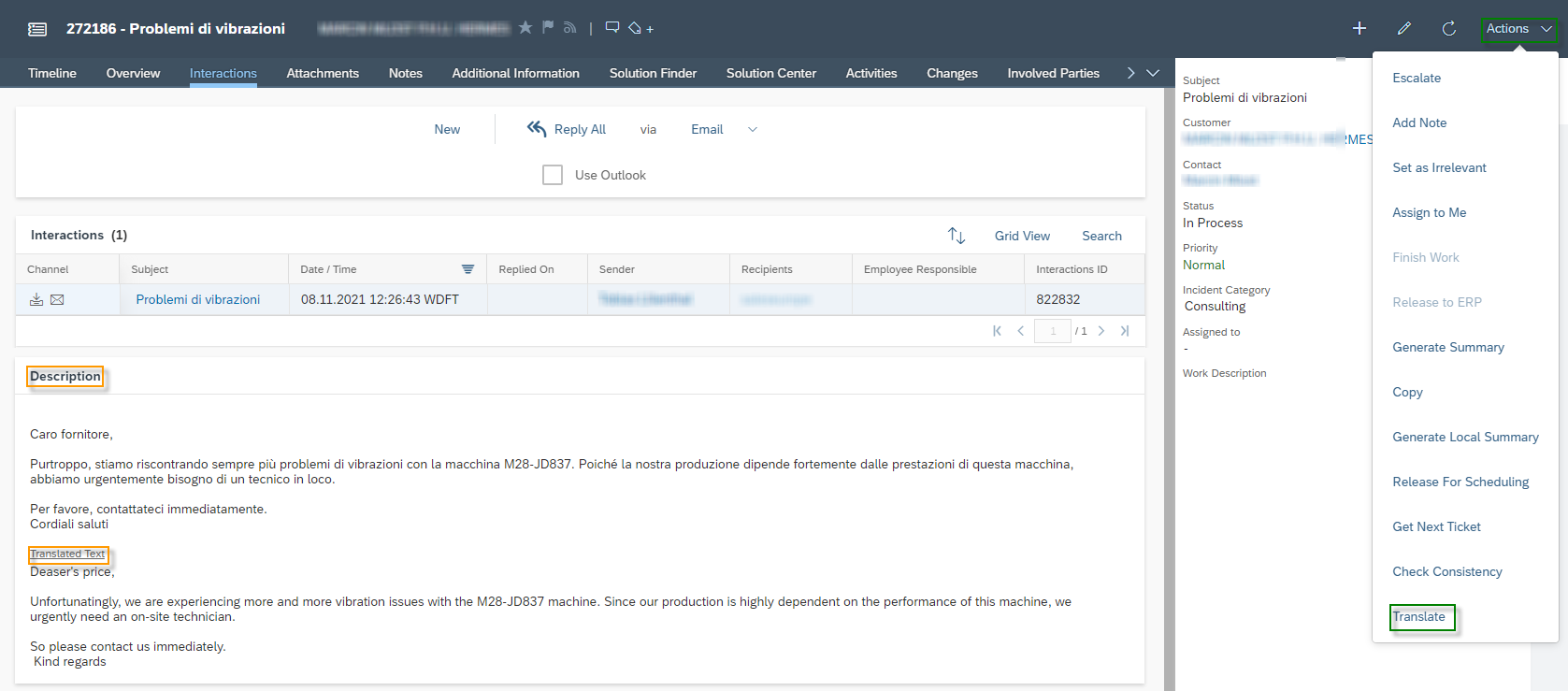
You have the possibility to test the translation capability of the module. To do this, click the More Options ![]() button and then Test.
button and then Test.

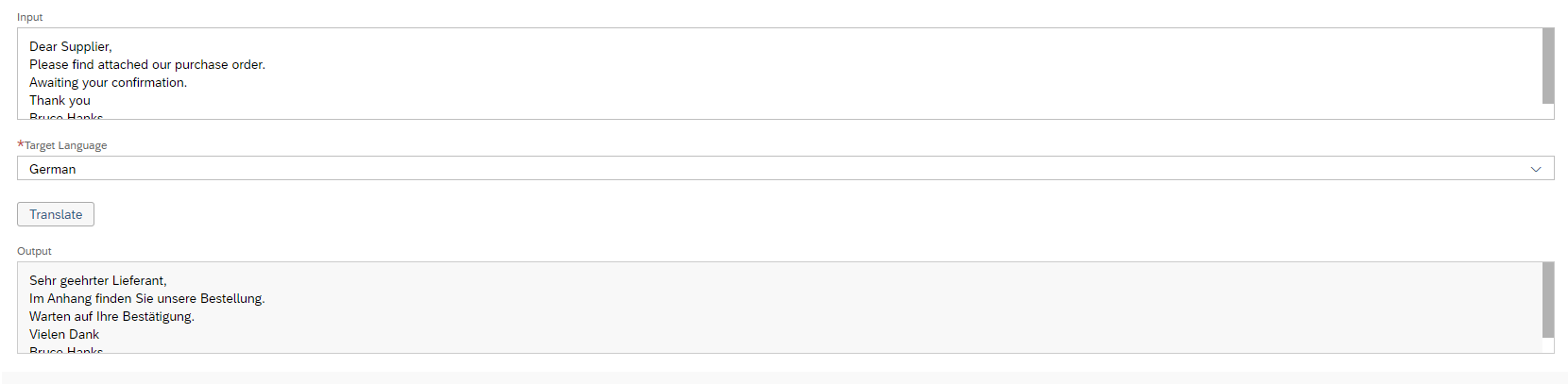
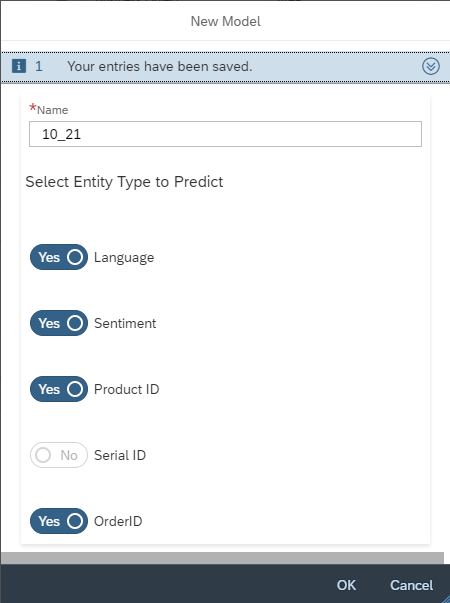

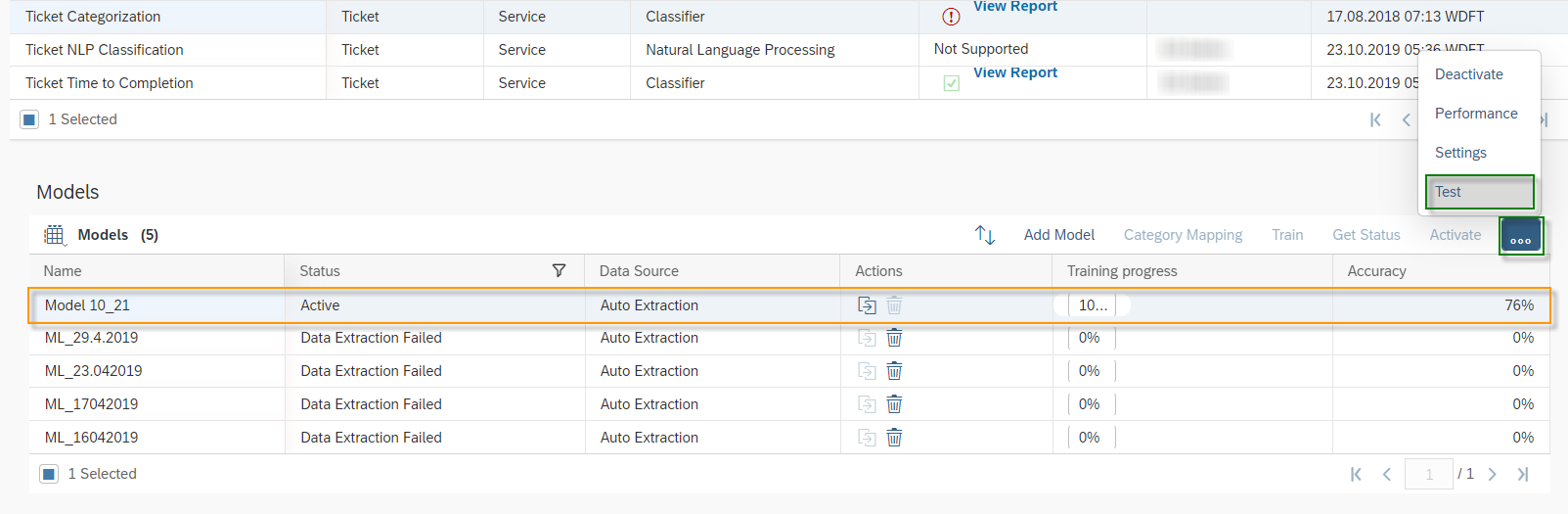
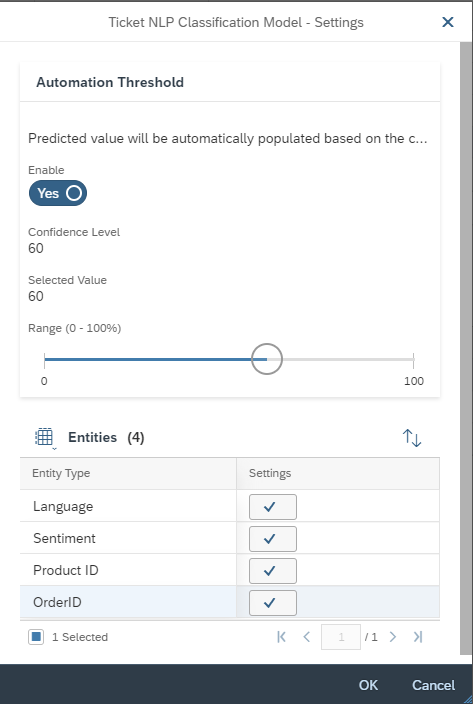
After the activation of the Model, you have to change the settings of your Model. Click on the More Options Button and then on Settings. Here you have to set the threshold for the Ticket NLP Classification. The Categorization of a newly created ticket is done in two steps. The first step is the calculation of a confidence of the selected entities, e.g., Language, Sentiment, etc. In the second step, this confidence is compared with the threshold. If the confidence is smaller than the threshold, then the machine does not act, and no categorization is performed. You are also able to deactivate ![]() entities here at any time or reactivate
entities here at any time or reactivate ![]() them back again.
them back again.
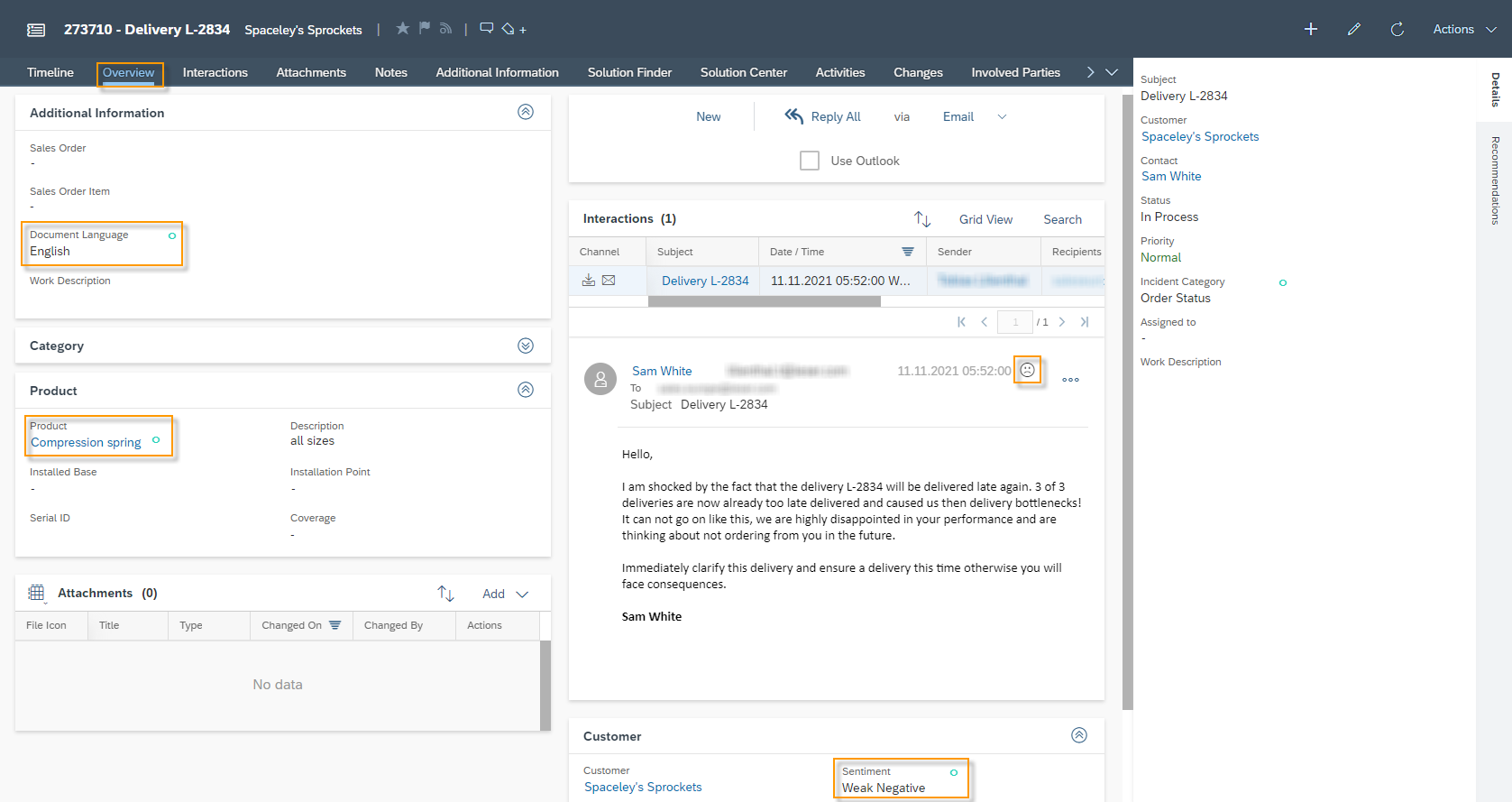
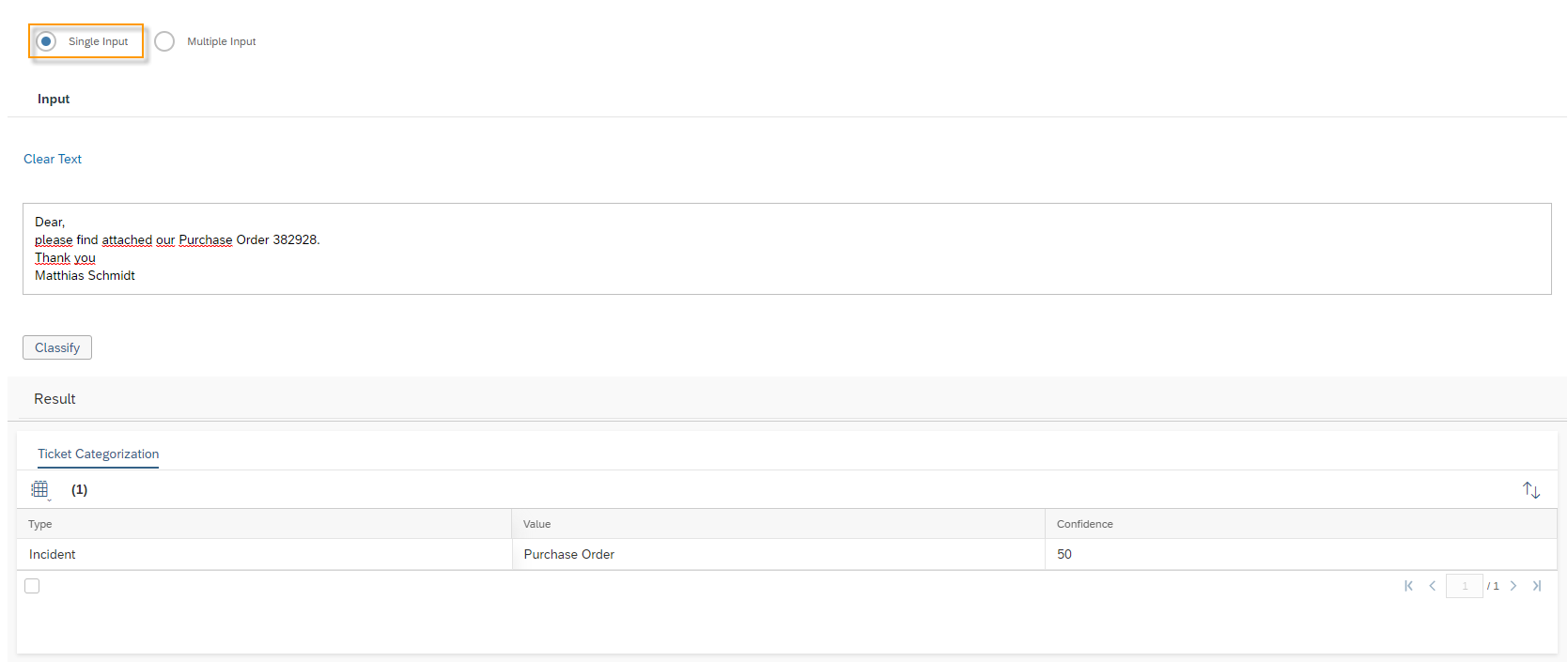
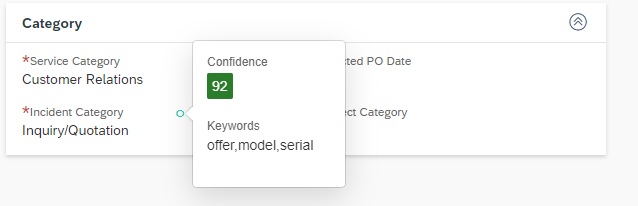
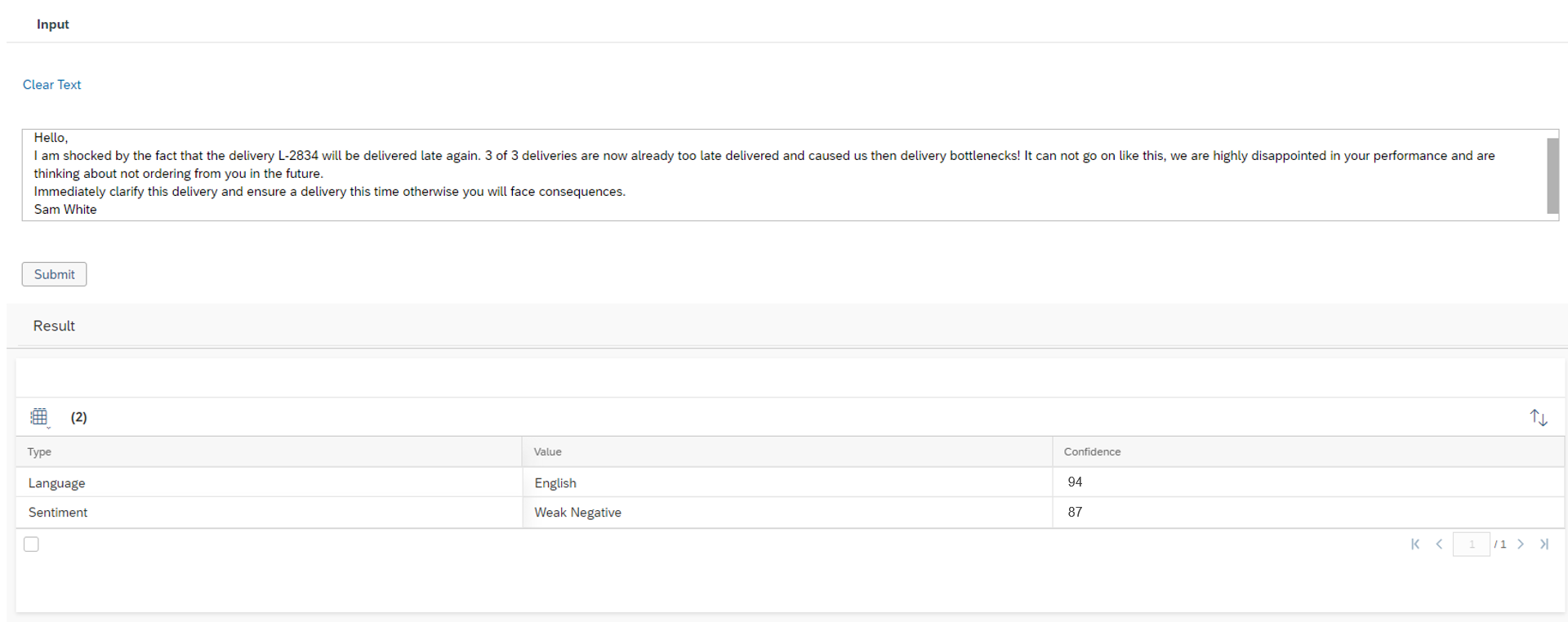
For this Model it is also possible to test the Prediction. To do so click on the More Options ![]() Button and then on Test. Here you will find an input text field, where you can put a text of an email in. Click the Submit button. The Model will return the trained entities Type, with the predicted Value and the Confidence. In the example shown you see that the customer is complaining about a delayed delivery, the whole text is in English. The Model returns the entity Language the value English with a confidence of 94%. The second entity Sentiment – which describes the mood of the customer – is predicted with the value Weak Negative with a confidence of 87%.
Button and then on Test. Here you will find an input text field, where you can put a text of an email in. Click the Submit button. The Model will return the trained entities Type, with the predicted Value and the Confidence. In the example shown you see that the customer is complaining about a delayed delivery, the whole text is in English. The Model returns the entity Language the value English with a confidence of 94%. The second entity Sentiment – which describes the mood of the customer – is predicted with the value Weak Negative with a confidence of 87%.
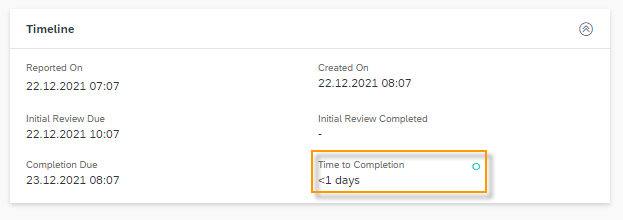
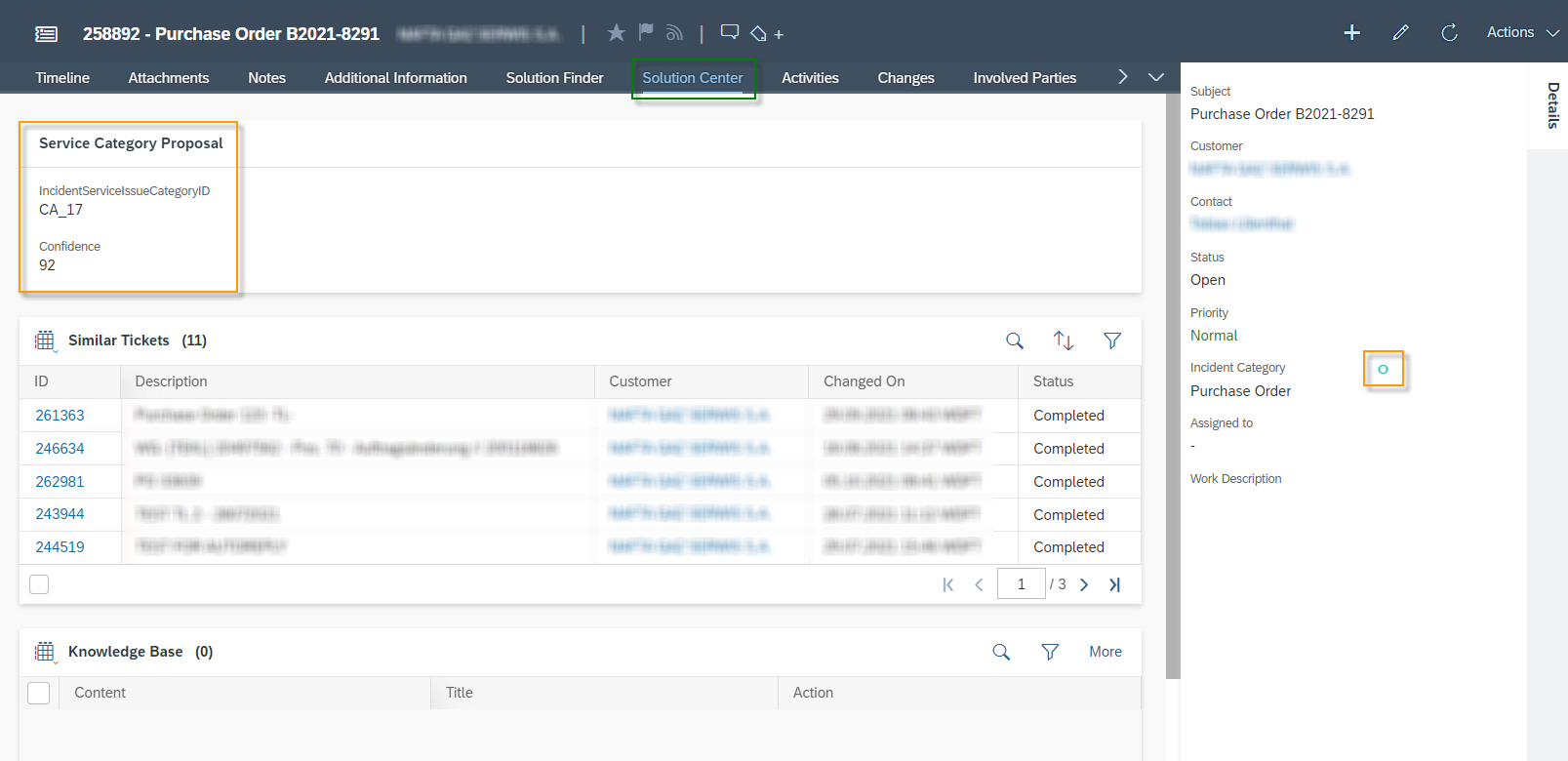
In the Ticket you will find the predicted values in the Overview Tab. The green circle indicates that this value was predicted by your machine learning model. For the Sentiment you will find following possible values:
- Not Available
- Strong Positive
- Weak Positive
- Neutral
- Weak Negative
- Strong Negative
Basically, what the NLP technology is doing here, is to extract the emotions from the written text by the customer and indicates if this are positive emotions or negative emotions. Where the type of emotion – e.g., happy vs. relieved are both positive emotions or angry vs. sad are both negative emotions – does not matter. Besides the Sentiment you will also find emoji’s next to an incoming e-mail in the service ticket, where you can check on the first view the emotional level of this e-mail:
 Negative
Negative Neutral
Neutral Positive
Positive